↓こんなサーフィンの動画を

Tune-A-Videoでいらすとや風にすることができました。

また、「サーフィンする宇宙飛行士」のようなプロンプト(テキスト)を与えることで、動画の一部を変化させることもできました。

Tune-A-Videoとは
Tune-A-Videoとは機械学習の手法のひとつで、大雑把に言うと、Stable Diffusionのような「テキストから画像を生成する拡散モデル」を使って既存の動画をプロンプト(テキスト)で指定した内容に変化させることができます。

(Tune-A-VideoのGitHubページより引用)
手法
Tune-A-VideoのGitHubで公開されている実装はStable Diffusionに対応していますが、今回はいらすとや風の動画を作りたかったので、通常のモデルの代わりに以前自分が作った「いらすとや風画像生成モデル」を使用しました。
動画の学習は以下の記事を参考にし、Google Colab Pro+でプレミアムクラスのGPU(Tesla A100、40GB)を使いました。
あとはひたすら学習率、学習ステップ数、プロンプト、シード等をいろいろ試していい動画が作れるまで粘りました。
生成できた動画いろいろ
せっかくなので、サーフィン動画を学習させたモデルに色々なプロンプト(テキスト)を与えてみました。
サーフィンする猫
不思議な色ですが、なかなか悪くなさそうです。

サーフィンする忍者
多少腕が消えたりしていますが、笑顔はいらすとや風になっています。

サーフィンするキノコ
何故か赤いキノコばかり生成されました。

サーフィンする脳みそ
さすがに厳しかったようです。

流れ星を眺める女の子
試しにサーフィンと関係ないプロンプトを与えてみましたが、やはり無理でした。フレーム間の一貫性がなくランダムな感じの動きになってしまいました。

苦労したこと
上ではさらっと「粘りました」と書きましたが、うまくいくハイパーパラメーターの組み合わせやシード値の探索には骨が折れました。
シード値の探索
例えば、以下の動画は同じ学習後のモデルを使いシード値だけを変えて出力したものです。

ご覧のように、一番左の動画はきれいな一方、他の動画は途中で髪型が変わったり首から上が一瞬消えたりしています。 同じ学習後のモデルでもシード値次第でここまで違う結果になるので、ハイパーパラメーターを変えてモデルを作る度に、数十個のシード値に対して動画生成をさせて本当にいい動画が出ないモデルかどうかを確かめていたため手間がかかりました。
元動画の実写スタイルの過学習
また、Tune-A-Videoでモデルを学習する際に、学習元の動画のスタイル(実写)を過学習してしまい、いらすとや風のスタイルで出力できなくなる場合もありました。 以下は異なる学習率や学習ステップ数でサーフィン動画を学習させた後に「パーティーハットをしながらサーフィンする人」の動画を出力させたもので、右に行くほど学習が進んだモデルの出力になっています。

今回の元動画は実写なので、学習率を上げたり学習ステップ数を増やしたりすればするほど実写風の動画が生成されやすくなる傾向がありました。一方で、学習率を下げ過ぎたり学習ステップ数を減らしたりすると、今度は元動画の特徴(例:正面に向かってサーフィンする)を捉えられなかったり、フレーム間の一貫性(例:波が少しずつ変化する)を保てなかったりといった問題が出てきてしまいました。
この点に関しては「学習率を下げて頻繁にvalidationの出力をさせ、丁度いい学習ステップ数を探し当てる」という対策を取って対処しました。
動画学習時と動画生成時に与えるプロンプトの調整
Tune-A-Videoの動画学習時のプロンプトと動画生成時のプロンプトに共通の単語が多く含まれている場合にも、上と同じく元動画の実写スタイルに引っ張られる問題が発生しやすいようです。
検証のために「サーフィンする男性(A man surfing)」というプロンプトを使って実写のサーフィン動画をモデルに学習させた後、「サーフィンする男性(A man surfing)」(左)と「サーフィンする男の子(A boy surfing)」(右)というプロンプトを与えて動画を生成させてみました。
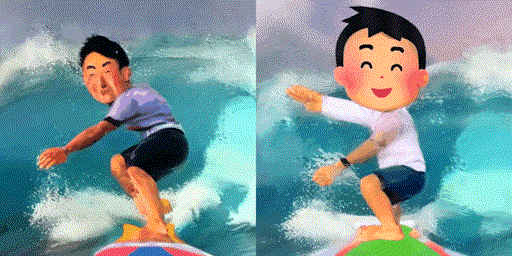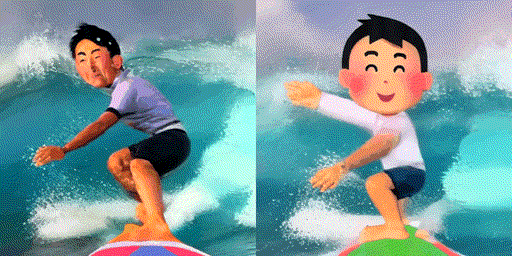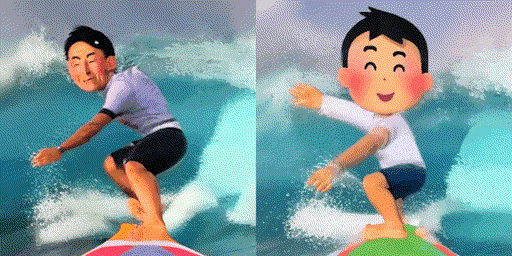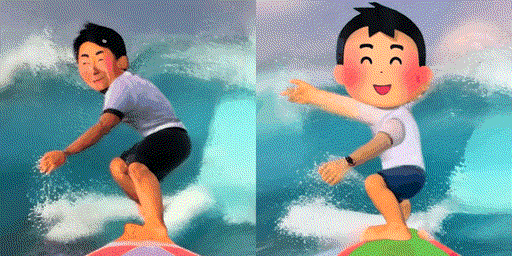
左の「男性(man)」という単語を与えた場合の動画は若干実写風であるのに対して、右の「男の子(boy)」はいらすとや風で動画を生成することに成功しています。このことから、「サーフィンする男性」というプロンプトで実写のサーフィン動画を学習させると、「サーフィン」と「男性」という概念に動画のスタイルの情報(実写)も結び付けられてしまっているのではないかと推測できます。
一方、動画学習時と生成時のプロンプトの単語を一切被らないようにした場合、今度は元動画の構図を完全に無視した動画が生成されてしまうようです。例えば動画学習時のプロンプトを「実写」に、生成時のプロンプトを「サーフィンする男性」にしたところ、学習率が高かったとしても、元動画にはない木が背景に出てきたりフレーム間の一貫性がなくなって体の一部が突然消えたりといった問題が発生しました。
そのため、動画学習時と動画生成時のスタイルが異なる場合、「学習時と生成時のプロンプトが過度に被らないようにしつつも多少は共通の単語を入れる」といった工夫が必要です。
おわりに
昨年Stable Diffusionが公開されてからの技術の進歩が非常に早く、毎日が驚きの連続です。VALL-Eのような優れた音声合成技術も揃いつつあるため、動画自動生成が実用レベルになるのも時間の問題かもしれません。