トンネルの多いTXからこんにちは.
今日はid:syou6162先生が主催するTsukuba.R#4で場違いなLTをする予定です.タイトルはなんと「Rで学ぶBrainf*ck」.わざわざRでBrainf*ckを学ぶ必要性なんて微塵も感じられませんね!
発表スライドをslideshareにアップしておきました.
http://www.slideshare.net/mickey24/rbrainfck-1085191
興味がある方はご覧ください.
トンネルの多いTXからこんにちは.
今日はid:syou6162先生が主催するTsukuba.R#4で場違いなLTをする予定です.タイトルはなんと「Rで学ぶBrainf*ck」.わざわざRでBrainf*ckを学ぶ必要性なんて微塵も感じられませんね!
発表スライドをslideshareにアップしておきました.
http://www.slideshare.net/mickey24/rbrainfck-1085191
興味がある方はご覧ください.
先ほどのfib(n)は、nの値が大きくなると計算量が指数関数的に爆発してしまいます。
例えばfib(5)を実行すると、以下のように展開して計算されます。
fib(5) -> fib(4) + fib(3) -> fib(3) + fib(2) + fib(2) + fib(1) -> fib(2) + fib(1) + fib(1) + fib(0) + fib(1) + fib(0) + 1 -> fib(1) + fib(0) + 1 + 1 + 0 + 1 + 0 + 1 -> 1 + 0 + 1 + 1 + 0 + 1 + 0 + 1 -> 5
展開中にfib(0)〜fib(3)を何度も呼び出しているのが分かると思います。
fib(1)なんかはトータルで5回も計算しています。
また、fib(6)を計算しようとすると、上記のfib(5)とfib(4)が呼び出され、さらに関数呼び出しの回数が増えてしまいます。
fib(30)とか計算しようとすると時間がかかりすぎて固まります。
というわけで、計算量を抑えた動的計画法版のfib(n)も定義してみました。
書いてみた結果がこれだよ。
fib <- function(n){ if (n == 0) { return(0) } x <- numeric(max(n,2)) x[1] <- x[2] <- 1 m <- 3 while (m <= n){ x[m] <- x[m-1] + x[m-2] m <- m + 1 } x[n] }
また非常にC言語っぽいプログラムですみません。
Rは1オリジンの言語なので、x[0] <- 0みたいなことができませんでした。
1オリジン爆発しろ。
この関数では、fib(3)、fib(4)、fib(5)、...と下から順に計算していき、最終的にfib(n)を求めます。
numeric()でn次元(最低でも二次元)のゼロベクトルを用意し、そこにフィボナッチ数の計算結果をどんどん蓄えていきます。
こうすれば、計算途中でfim(m)を求めるときに、一度計算したfib(m-1)とfib(m-2)を再計算せずに値を求めていくことが可能になります。
nに比例した回数の計算を行うので、この関数の計算量はO(n)です。
fib(30)も一瞬で計算できます。
動的計画法いいよ動的計画法。
ちなみに再帰関数の場合でもメモ化すれば計算量を減らすことができます。
メモ化(Wikipedia)
http://ja.wikipedia.org/wiki/%E3%83%A1%E3%83%A2%E5%8C%96
あまりRの練習になりませんでした。
何の練習だこれ。
昨晩TwitterでRとフィボナッチ数のことをぼやいていたら、id:syou6162先生が「一行で書けるよ」的なことを仰っていたので、早速例を見せてくれるようにお願いしました。
そして見せてもらった結果がこれだよ。
(function(n){ifelse(n>1,Recall(n-1)+Recall(n-2),ifelse(n==1,1,0))})(1:10)
おお、何かよく分からないけど一行カッコイイ!流石id:syou6162先生!!
さっそく実行してみました。
> (function(n){ifelse(n>1,Recall(n-1)+Recall(n-2),ifelse(n==1,1,0))})(1:10) [1] 1 1 2 3 5 8 13 21 34 55
ちゃんとフィボナッチ数列の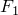 から
から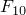 までの値が返ってきました。
までの値が返ってきました。
最初に見た時はRecall()がどういう関数なのか分からなかったのですが、Rのヘルプによると現在定義している関数を再帰呼び出し(recall)する関数だそうです。
なるほど、無名関数で再起を行う場合はRecall()を使えばいいのですね。メモメモ。
ちなみにRecall()のヘルプはRで以下のようにすれば見ることができます。
?Recall
Rでフィボナッチ数を計算する関数を書いて遊んでみました。
n番目のフィボナッチ数を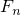 で表すと、
で表すと、
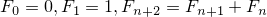
と定義されます。一般項がひとつ前の項とさらにひとつ前の項の和になっています。
この漸化式で表わされる数列をフィボナッチ数列といい、最初の数項は以下のようになります。
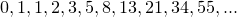
とりあえずRの練習がしたかったので、試しにRを使ってフィボナッチを計算する関数を定義してみました。
漸化式の定義通りに再帰呼び出しを使って書いてみた結果がこれだよ。
fib <- function(n){ if (n == 0) { return(0) } if (n == 1) { return(1) } fib(n-1) + fib(n-2) }
うん、全然Rの練習にならなかった。
今すぐにC言語に落とせそうなコードですね。笑
少し前に、Rの勉強をするべくGCJの問題をRで解いてみました。
Online Round 1A: Problem A. Minimum Scalar Product
二つのn次元ベクトルv1、v2が与えられる。
ベクトルの各要素は整数である。
v1とv2のそれぞれについて要素を並び替え、v1とv2の内積を計算した結果をPとするとき、Pの最小値を求めよ。
問題の原文はこちら。
入力のフォーマットは以下の通り。まず最初に整数Tがひとつ与えられます。
T
T: テストケース数(入力データセット数)
次に、各テストケースごとに以下の入力が与えられます。
n x1 x2 ... xn y1 y2 ... yn
n: ベクトルv1, v2の要素数(次元)
x1, x2, ..., xn: ベクトルv1の各要素の値(整数)
y1, y2, ..., yn: ベクトルv2の各要素の値(整数)
出力のフォーマットは以下の通り。各テストケースについて以下の出力を行います。
Case #X: Y
X: テストケースの番号(1,2,...,T)
Y: 内積の最小値
入力データファイルはSmall datasetとLarge datasetの二種類があります。
Small dataset T = 1000 1 ≤ n ≤ 8 -1000 ≤ xi, yi ≤ 1000 Large dataset T = 10 100 ≤ n ≤ 800 -100000 ≤ xi, yi ≤ 100000
Large datasetだとベクトルの要素数が最大800まであるため、要素の順列をとって内積をひとつひとつ計算するプログラムを書くと800! ≒ 7.7 * 10^1976で計算量が爆発します。
v1とv2の各要素をそれぞれ昇順・降順にソートして内積をとった値が求める最小値となるので*1、それを計算して終了です。
lines <- 0 file <- "A-large.in" solve <- function() { n <- scan(file, skip=lines, nmax=1) lines <<- lines + 1 v1 <- scan(file, skip=lines, nmax=n) lines <<- lines + 1 v2 <- scan(file, skip=lines, nmax=n) lines <<- lines + 1 sum(sort(v1) * sort(v2,decreasing=T)) } t <- scan(file, skip=lines, nmax=1) lines <- lines + 1 out <- matrix(0, t, 3) for (a in 1:t) { out[a,] <- c("Case", sprintf("#%d:", a), solve()) } write(t(out), "A.out", ncolumns=3)
肝心の答えを計算している部分は「sum(sort(v1) * sort(v2,decreasing=T))」のところだけです。
こんなベクトル計算もサラッと書けます。
さすがR。
*1:誰か証明して下さい><
id:syou6162 先生が主催するTsukuba.R#1に参加してきました。
皆さんお疲れ様でした!
Tsukuba.Rは統計処理「R」について学ぶ勉強会です。
http://wiki.livedoor.jp/syou6162/d/%a5%c8%a5%c3%a5%d7%a5%da%a1%bc%a5%b8
Rについての収穫が多かったのは勿論ですが、ネタ発表もあったりしていろいろ楽しむことができました。
これは次回もぜひ参加したいですね。
以下、印象に残ったことなどを書いていきます。
話の内容を把握したりサンプルコードを動かすのに精一杯でほとんどメモを残すことができませんでした。ごめんなさい。
それにしても、Twitterを見ていて思いましたが、Rの習得が速い人多すぎです。
私もRでGCJのプログラムを書いたりしていますが、そんなネタ的なことばっかりしてないで、もっと実用的な統計処理プログラムを書く練習をした方がいいような気がしてきました。
では最後に、Rとの素敵な出会いの場を作ってくれたid:syou6162++。